
Text Generation from a Corpus of Dictators

Data Scientists can be very quirky individuals and this is a perfect example. NLP is of great interest to me. What language communicates underneath the surface, fascinates me. When applied to data another word opens once you verterize your vocabulary. The nuance of a conversation. The context embedded, simply becomes a matter of calculated probability around the vocabulary.
To test this theory, I employed a recurrent neural network with Keras on a Tensorflow backend.
Could I train an RNN to speak like a dictator? Would the speech be convincing?
I always like to explore basic NLP on any text to look at word frequency.
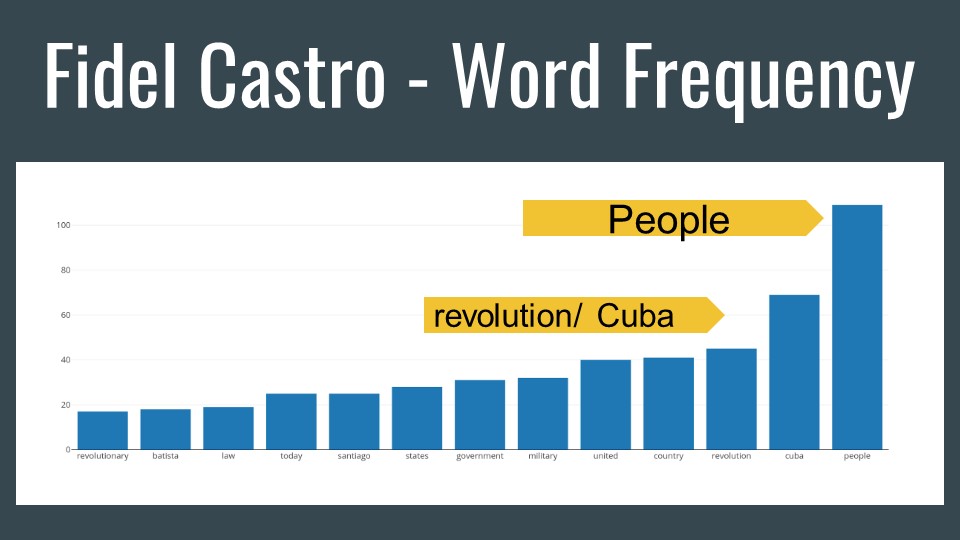
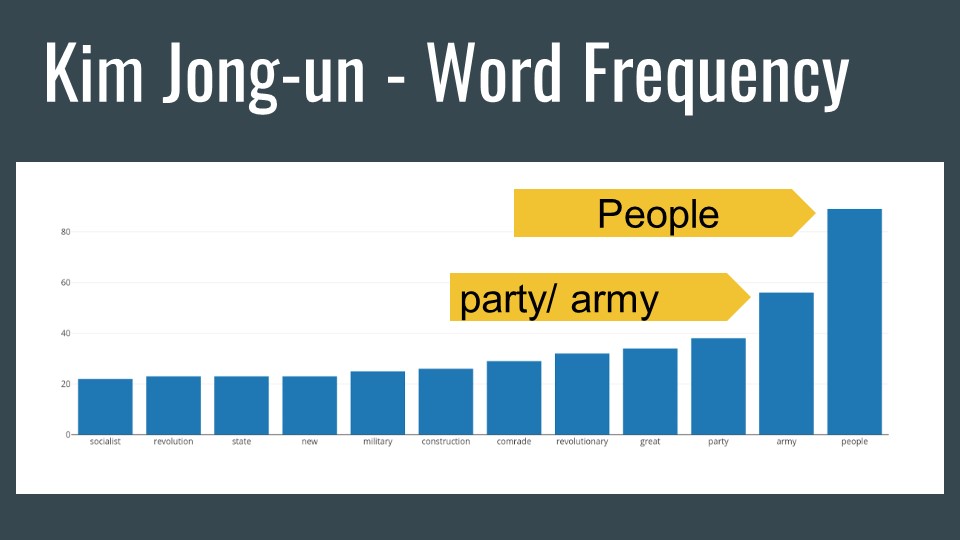
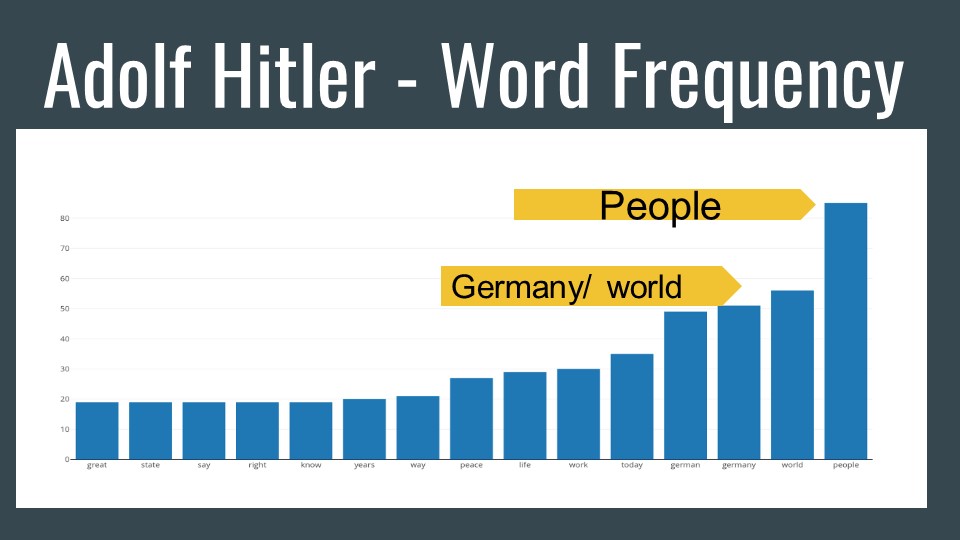
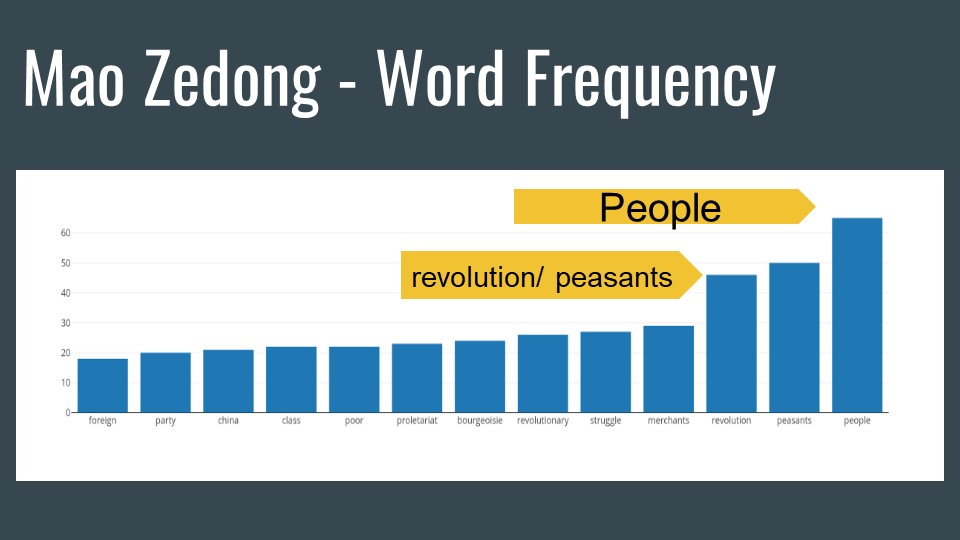
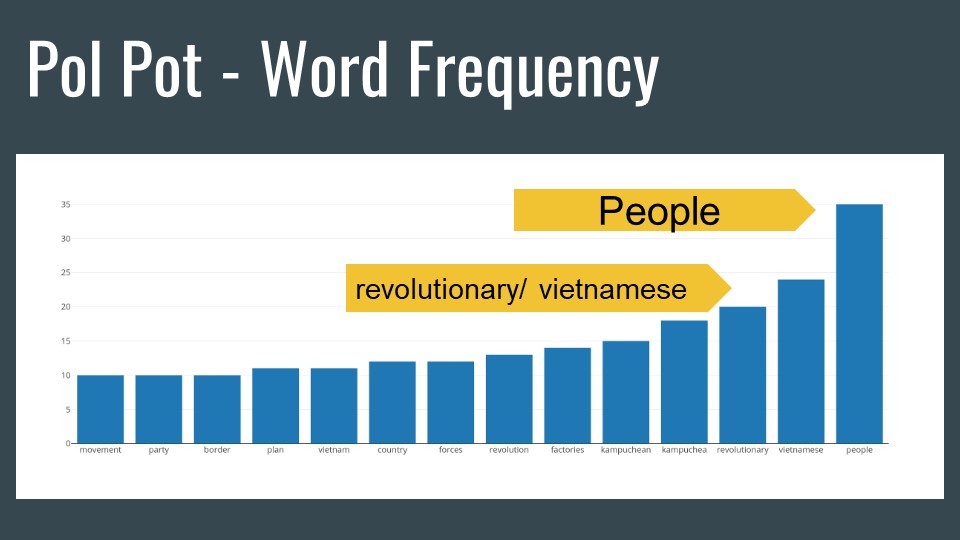
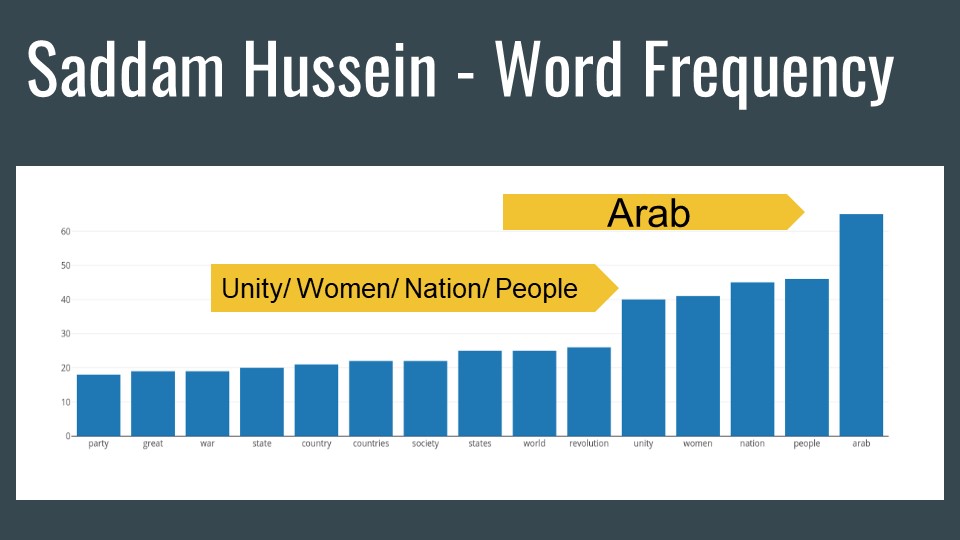
Word frequency, although basic, never fails to reveal ideas. As you can see some of the most infamous dictator wrap their entire rhetoric around people. Every dictator in this corpus had at least 10,000 words available to study. In all the corpus contained over 100K words.
Neural nets are like babies, in that everything ingested must be processed down to morsels it can take. The LSTM (long term short term memory) model I used is no different. All words must be vectorized, meaning they receive a number representation.

The network now sees the corpus like this. Now in generating text. I have to turn the entire corpus into a probability of words, so I divided the vector dictionary by the total number of words and “PRESTO”, every word is a value between 0 and 1. Oh, if life could only be this simple. Well, actually it is, but we will catch up to its simplicity within the next 20yrs, I’m sure of it.

The Code
def tokenize_and_process(text, vocab_size=10000):
#list for clean text from above
#all_text_to_list
T = Tokenizer(num_words = vocab_size)
#fit tokenizer
T.fit_on_texts(all_text_to_list)
#turn input text into sequence of integers
data = T.texts_to_sequences(all_text_to_list)
#extract vocabulary word/ index pairings from tokenizer, so we can go back and forth
word_to_index = T.word_index
index_to_word = {v: k for k, v in word_to_index.items()}
return data, word_to_index, index_to_word, T
#Drawing values from above function tokenize_and_process
data, word_to_index, index_to_word, T = tokenize_and_process(all_text_to_list)
seq_length = 7
data_X_new = []
data_y_new = []
for i in range(0, word_count - seq_length, 1):
seq_in = big_text_list[i:i + seq_length]
seq_out = big_text_list[i + seq_length]
data_X_new.append([word_to_index[words] for words in seq_in])
data_y_new.append(word_to_index[seq_out])
n_patterns_new = len(data_X_new)
print("Total Patterns: ", n_patterns_new)
# reshape X to be [samples, time steps, features]
X = np.reshape(data_X_new, (n_patterns_new, seq_length, 1))
# normalize
X = X / float(vocab_count)
# one hot encode the output variable
y = np_utils.to_categorical(data_y_new)
# Setup the NEW LSTM model
model_new = Sequential()
model_new.add(LSTM(256, input_shape=(X.shape[1], X.shape[2])))
model_new.add(Dropout(0.2))
model_new.add(Dense(y.shape[1], activation='softmax'))
model_new.compile(loss='categorical_crossentropy', optimizer='adam')
# define the checkpoint/ save the weights
filepath="weights-improvement-{epoch:02d}-{loss:.4f}.hdf5"
checkpoint = ModelCheckpoint(filepath, monitor='loss', verbose=1, save_best_only=True, mode='min')
callbacks_list = [checkpoint]
Context is Probability
The network scans through the entire corpus. I arbitrarily chose a 7 word input pattern. I felt it was short enough to not overwhelm the the net, but long enough to gain “context.” The network scans every 7th word and stores it as an X variable. It then takes the 8th word as a the y variable. Its basically a linear regression in which the features are the previous 7 words and the 8th word is our predicted value based upon the previous 7 words. Isn’t that cool? It basically how we as human understand each other.
